Optimization Algorithms
1.Why
Nhiều bài toán trong Machine Learning đưa về việc tối ưu một hàm số gọi là cost function (hàm giá trị) hoặc loss function (hàm mất mát), tức là tìm giá trị của tham số sao cho hàm đạt giá trị nhỏ nhất, trong đó là một biến số trong không gian 1 chiều (1 biến) hoặc chiều (với trường hợp tối ưu hàm nhiều biến).
2.Gradient descent
Chúng ta cùng xét ví dụ đơn giản, tối ưu hóa hàm . Đây là đồ thị hàm số này.
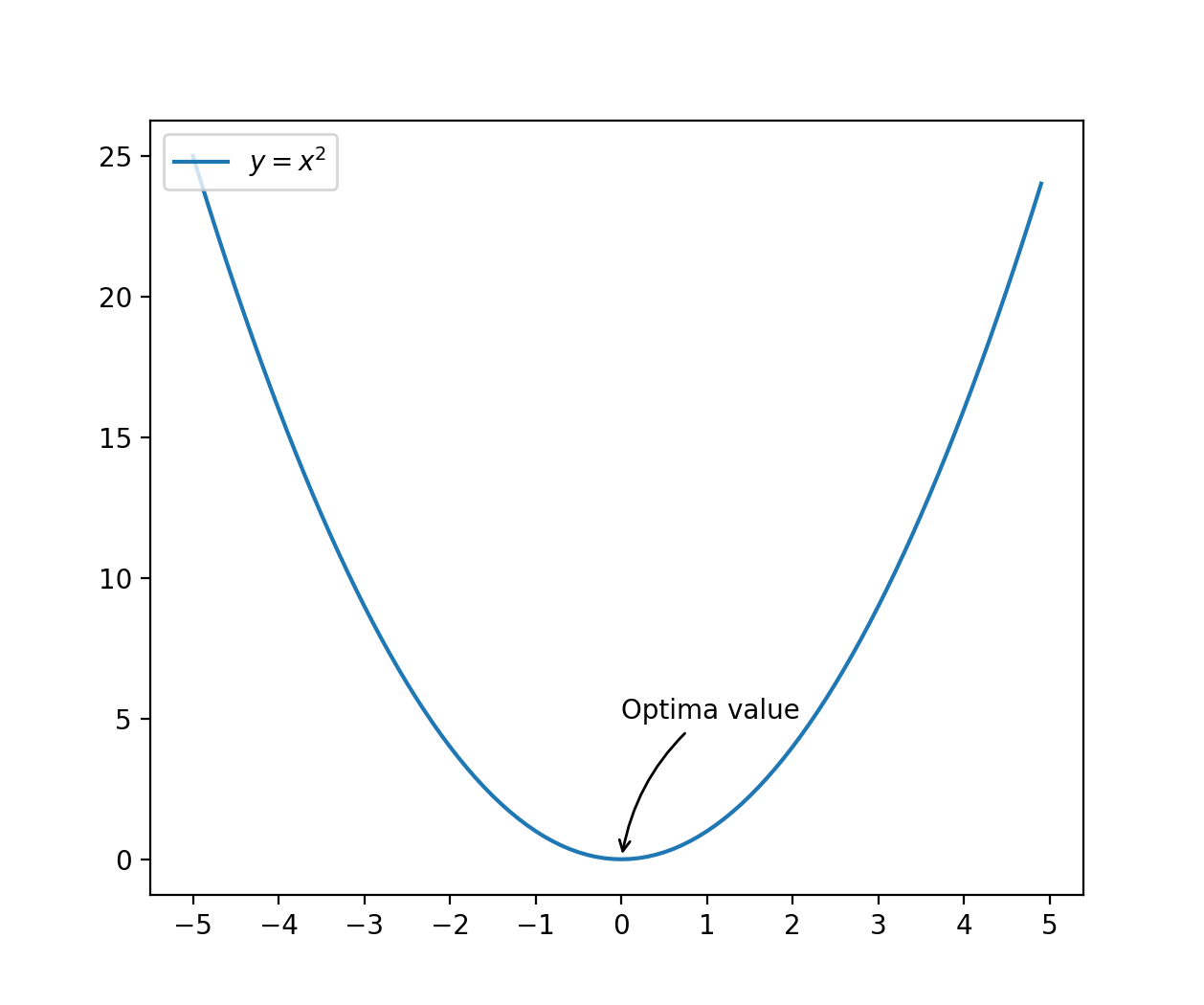
Dễ dàng thấy ngay, giá trị nhỏ nhất của hàm số này là , đạt được tại . Bằng các công cụ đại số đã học thì nhớ lại rằng, đạo hàm của một hàm số tại điểm cực trị (optima value) bằng 0, nên thực tế bài toán tối ưu đưa về việc giải phương trình trong đó là kí hiệu đạo hàm của hàm y.
Việc giải phương trình không phải lúc nào cũng đơn giản như ví dụ ở trên vì máy tính không biết tính đạo hàm của một hàm số bất kì (giả sử hàm ). Do đó cần một phương pháp tổng quát để tính được xấp xỉ giá trị của mà tại đó đạt giá trị nhỏ nhất. Một trong những thuật toán đó là thuật toán Gradient descent
2.1.Algorithm
Bước 1: Khởi tạo 1 giá trị random của
Bước 2: Thực hiện vòng lặp như sau, thay đổi giá trị của để giảm giá trị của cho đến khi đạt được giá trị nhỏ nhất.
Repeat until converge {
}
trong đó gọi là learning rate, còn kí hiệu là đạo hàm (hoặc đạo hàm riêng tại )
Khá đơn giản, nhưng để hiểu hơn một cách trực quan, chúng ta cùng xem hình minh họa dưới đây (nguồn: http://machinelearningcoban.com). Thuật toán Gradient descent thường được tưởng tượng giống như trọng lực của trái đất tác động lên hòn bi.
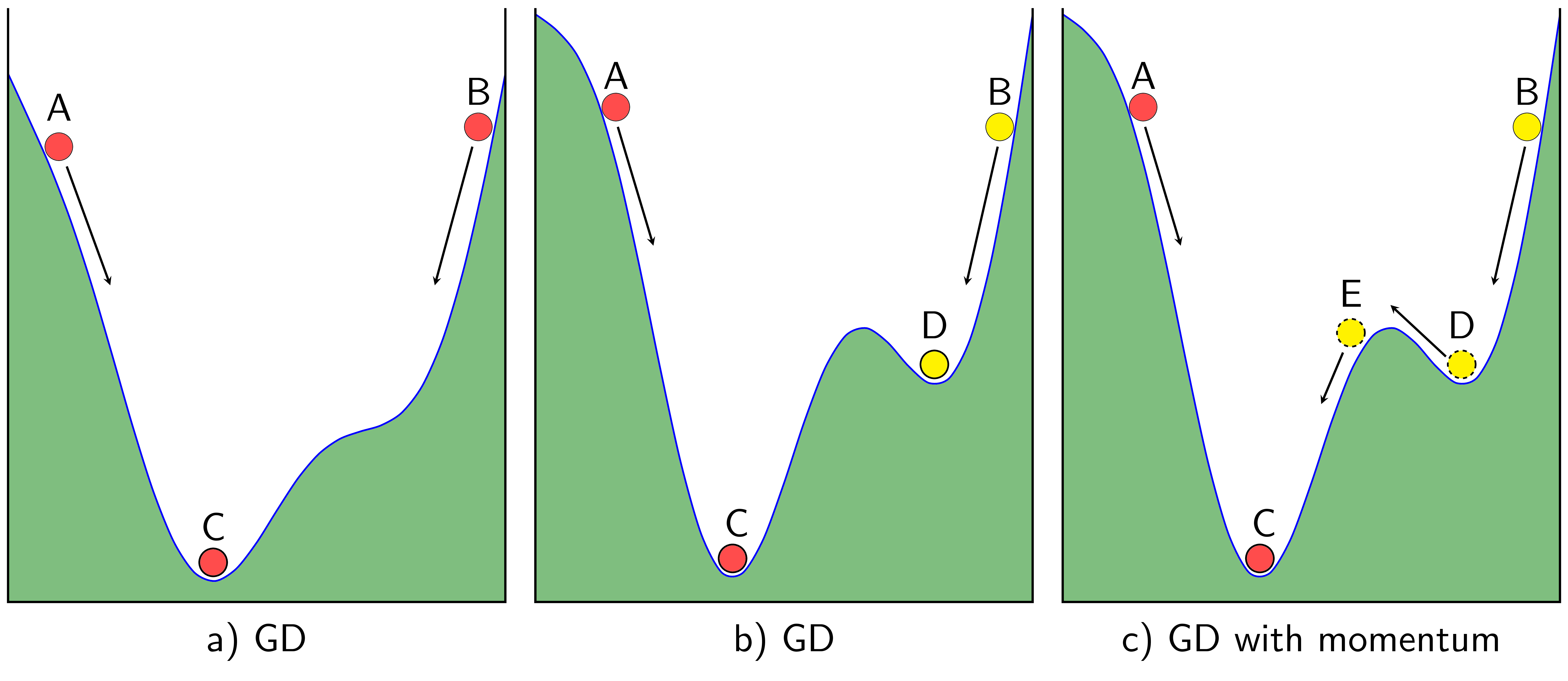
Giả sử chúng ta có một vật có hình dáng kích thước giống như màu xanh lá cây trong hình vẽ trên, đặt 1 hòn bi tại 1 điểm bất kì, trọng lực sẽ giúp cho hòn bi rơi xuống 1 điểm lõm nào đó, kiểu như nước chảy chỗ trũng. Còn đối với 1 hàm số bất kì, gradient descent (bước lấy giá trị hiện tại của trừ đi một giá trị nào đó được gọi là gradient descent) sẽ giúp cho biến về được giá trị biến cực tiểu địa phương nào đó (gọi là local minimum). Đối với hàm chỉ có 1 cực trị như ở trên trên, thì dù khởi hoặc tại vị trí nào đi nữa, thì kết quả cuối cùng cũng gần như nhau, nhưng như trường hợp của hình b) hoặc c) khi mà hàm số có 2 hoặc nhiều giá trị cực tiểu thì vị trí khởi tạo sẽ ảnh hưởng đến nghiệm cần tìm.
Trong trường hợp tốt nhất, chúng ta luôn mong muốn tìm được global minimum (điểm mà hàm số thực sự đạt giá trị nhỏ nhất trên toàn bộ tập giá trị) chứ không phải local minimum, nhưng với nhiều bài toán ML, các mô hình học (learning model) hoặc được xây dựng sao cho hàm giá trị (hàm mất mát) là hàm lồi (convex function) để đảm bảo chỉ có 1 cực trị, hoặc được xây dựng sao cho việc tìm được giá trị cực tiểu địa phương cũng làm cho thuật toán đạt được độ chính xác tương đối rồi, nên trước hết, không cần để ý đến chi tiết giá trị cực tiểu tìm được là cực tiểu địa phương hay cực tiểu toàn bộ.
2.2 Implementation
Dưới đây là ví dụ về một cách implement đơn giản đối với trường hợp tối ưu hóa hàm số .
'''
Simple implementation of gradient descent
'''
def cost(x):
return x*x
def grad(x):
return 2*x
# Random initialize the value of x
x = 11.0
# Learning rate
alpha = 0.01
# Loop for 1000 iterations
for i in range(1,1000):
x = x - alpha * grad(x)
# Value of x after 1000 iterations
print("Optima value of x = %f" % x)
Và đây là kết quả output (Not bad, haha…^^)
Optima value of x = 0.000000
Kết quả output tất nhiên là đúng với những gì chúng ta kì vọng, tuy nhiên có 1 số chỗ hơi “magic” như sau:
- Làm sao chọn được hệ số alpha
- Làm sao biết mà thực hiện lặp 1000 lần
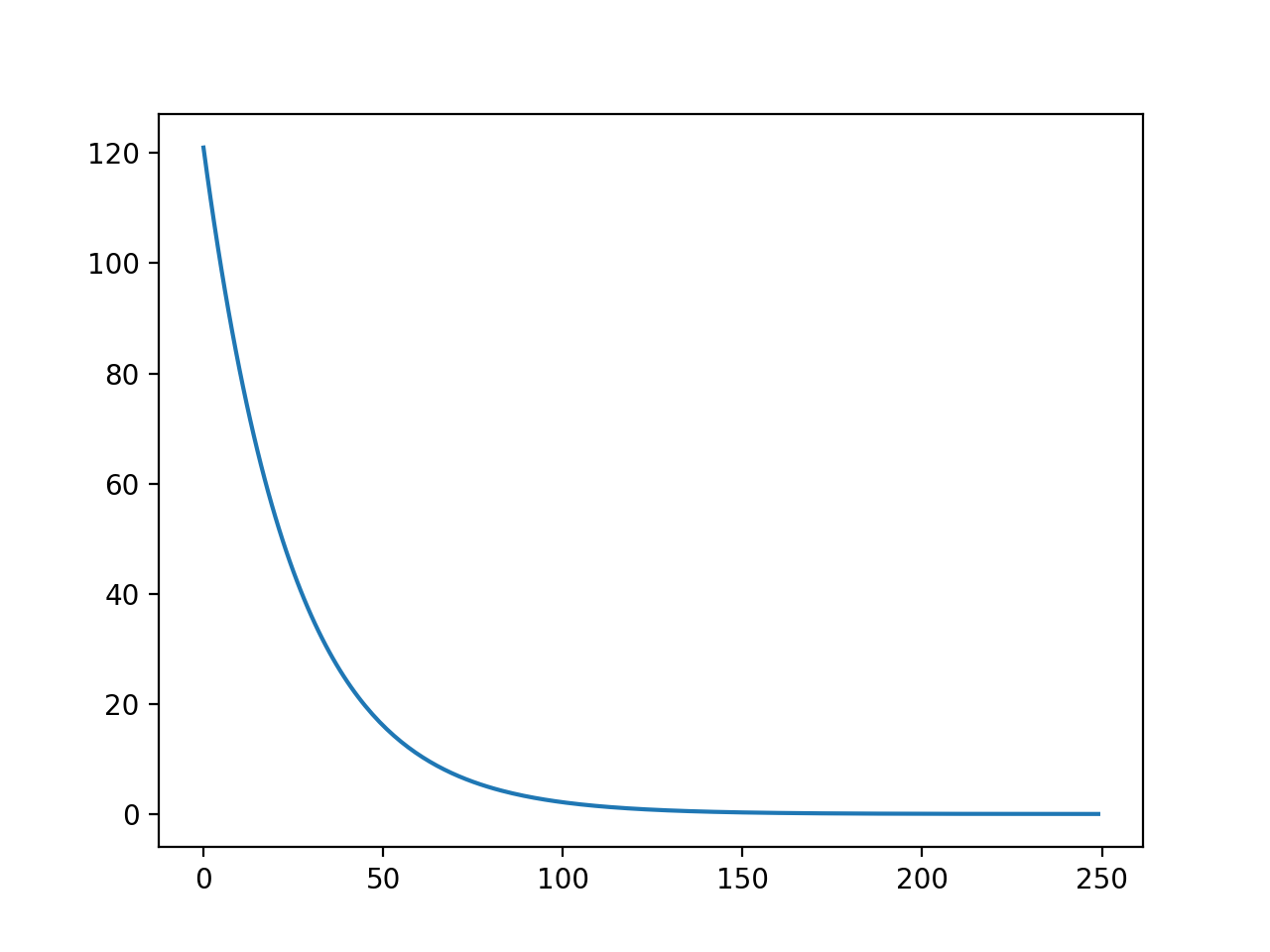
Nói một cách tóm tắt, chúng ta sẽ plot hàm theo số lần lặp.
| Learning rate alpha = 0.01 | Learning rate alpha = 0.03 |
|---|---|
 |
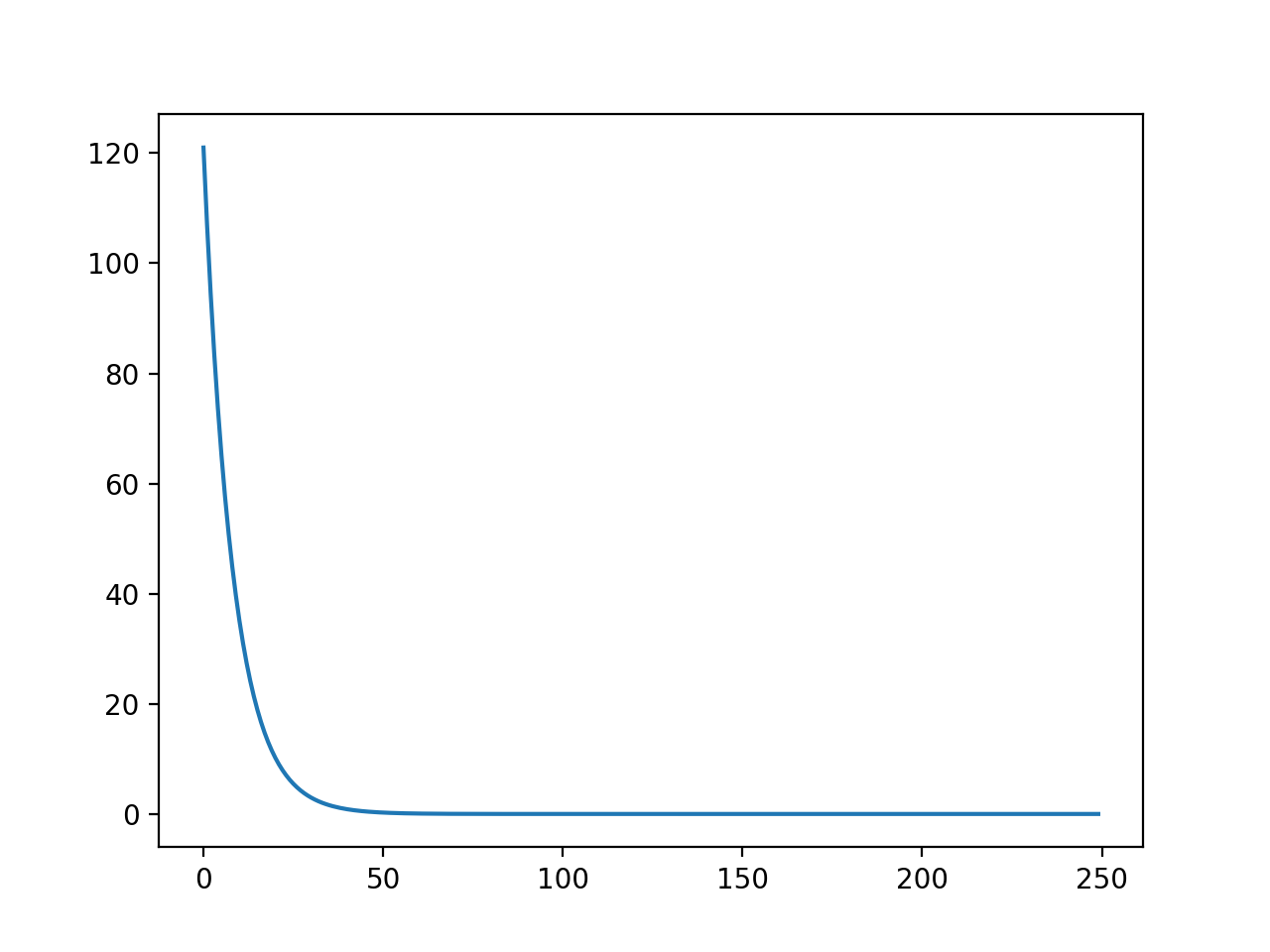 |
Lưu ý rằng, chúng ta luôn muốn thấy giá trị của hàm giảm theo số lần lặp, do đó trong trường hợp trên learning rate đều là giá trị tốt để implement thuật toán. Với trường hợp learning rate là 0.03 thì giá trị hàm giảm nhanh hơn. Trong khi cần khoảng 100 vòng lặp để đưa giá trị hàm về gần 0 trong trường hợp thì chỉ cần chưa đến 50 vòng lặp cho trường hợp .
Dưới đây là 1 số lưu ý khi implement thuật toán gradient descent
- Luôn plot giá trị của hàm cần tối ưu hóa theo số vòng lặp, đảm bảo rằng giá trị của hàm J luôn giảm theo số vòng lặp
Nếu giá trị của hàm J tăng, có thể learning rate quá cao, cần chọn giá trị nhỏ hơn. Hoặc công thức tính đạo hàm không đúng.
- Chọn hệ số learning rate sao cho thuật toán nhanh hội tụ về điểm local optima nhất.
2.3 Advanced optimization algorithms
Ví dụ trên là ví dụ đơn giản nhất để hiểu về thuật toán tối ưu hóa trên máy tính. Thực tế ngoài thuật toán trên còn có các thuật toán tương tự như dưới đây
- Conjugate gradient
- BFGS
- L-BFGS
- …
Tất cả các thuật toán này đều đi kèm trong các thư viện có sẵn, chúng ta không cần implement lại. Các thuật toán này có ưu điểm là không cần tự chọn learning rate và thường nhanh hơn so với thuật toán gradient descent trình bày ở trên.
Tham khảo thêm các hàm tối ưu hóa ở đây. Cách dùng chung đều là truyền vào cách tính cost function và gradient (đạo hàm riêng) của hàm đó, nhận lại giá trị trả về là giá trị của làm hàm đó nhỏ nhất.